What Is Robots.Txt? How To Optimize It For Your SEO?
May 16, 2024 | prashant@growth.cxThe robots.txt file is one of the first things you should check and improve when working on technical SEO. An issue or misconfiguration in your robots.txt file can cause serious SEO issues, affecting your rankings and traffic.
Search engine optimization (SEO) involves big and small website modifications. The robots.txt file may appear to be a relatively minor SEO element, but it can have a significant impact on your site’s accessibility and rankings.
In this blog post, you will discover what a robots.txt file is, why you need one, how to SEO optimize it, and how to ensure that search engines can enter it without issue.
What Is The Robots.txt File?
| A robots.txt file is a command that instructs search engine robots or crawlers on how to navigate a website. Directives serve as orders in the crawling and indexing methods, directing search engine bots, such as Google bots, to adequate pages. |
Robots.txt files, which reside in the root directory of sites, are also classified as plain text files. If your domain is “www.robotsrock.com,” your robots.txt file is located at “www.robotsrock.com/robots.txt.”
Robots.txt files serve two purposes for bots:
- Block crawling of a URL path. The robots.txt file, on the other hand, is not the same as no index robots.txt meta directives, which prevent pages from being indexed.
- Allow crawling through a specific page or subfolder if crawling into its parent has been disabled.
Robots.txt files are more like suggestions for bots than hard and fast rules — and your pages may still be indexed and appear in search results for specific keywords.
The files primarily manage the frequency and intensity of crawling and control the strain on your server. The file identifies user agents, which either refers to a particular search engine bot or expands the order to all bots.
For example, if you only want Google to crawl pages and not Bing, you can send them instructions as the user agent. With robots.txt, web developers or operators can prevent bots from crawling specific pages or sections of a site.
Why Use Robots.txt File?
Robots.txt is the solution for controlling when and what bots crawl.
One of the ways robots.txt files aid SEO is in the processing of new optimization actions. When you modify your header tags, meta descriptions, or keyword application, their crawling check-ins registration — and better search engine crawlers optimize your website based on positive advancements as soon as possible.
You want search engines to identify the changes you’re making as you integrate your SEO strategy or publish fresh content, and you want the outcomes to reflect these changes.
If you have a slow site crawling frequency, the indication of your improved site can slow down. Robots.txt can make your site more organized and efficient, but it will not directly improve your page’s ranking in the SERPs.
They adversely optimize your site so that it does not incur penalties, deplete your crawl expenditure, slow your server, or connect the wrong pages with link juice.
How to Find a Robots.txt File
To find the robots.txt file for a website, you need to add /robots.txt to the end of the domain URL.
For example, to see the robots.txt file for a website with the domain example.com, you would go to https://www.example.com/robots.txt.
Here’s a step-by-step guide:
- Open your web browser (Use any browser)
- Enter the URL: Type the main URL of the website in the address bar.
- Access the file: Adding/robots.txt after the domain and press enter.
This file is publicly accessible and tells web crawlers and robots which parts of the website they are allowed or disallowed from crawling. If a website does not have a robots.txt file, you might see a 404 error page indicating that the file does not exist.
How Does Robots.txt File Help In Improving SEO?
Although using robots.txt files does not guarantee first-page rankings, it is important for SEO. They are an essential technical SEO component that ensures the smooth operation of your site and the satisfaction of visitors. SEO aims to make your page load quickly for users, generate original content, and enhance your highly relevant pages.
Robots.txt is important for making your site available and accessible. Here are four ways to use robots.txt files to improve your SEO.
1. Keep Your Crawl Budget Intact
Crawling by search engine bots is useful, but it can affect sites that lack the muscle to manage bot and user visits. Googlebot allots a budgeted portion to each site based on its favorability and nature. Some web pages are larger than others, and some have massive authority, so they receive a larger payout from Googlebot.
Google does not define the crawl budget explicitly, but they do state that the goal is to highlight what to crawl, when to crawl, and how deeply to crawl it. The “crawl budget” is primarily the number of total pages that Googlebot crawls and indexes on a website in a given amount of time. The crawl budget is driven by two factors:
- The crawl rate limit restricts the crawling actions of the search engine so that it does not overpower your server.
- Crawl demand, prominence, and freshness all play a role in determining whether the site requires more or less crawling.
Because you don’t have an infinite supply of crawling time, you can use robots.txt to keep Googlebot away from unnecessary pages and direct them to the important ones. This will save your crawl budget and relieve you and Google of the burden of dealing with irrelevant pages.
2. Avoid Leaving Duplicate Content Footprints
Search engines dislike duplicate or outdated content, but they especially dislike manipulative duplicate content.
Duplicate content, such as PDF or printer-friendly editions of your pages, does not harm your site’s ranking. Bots, on the other hand, are not required to crawl duplicate website content and show them in the SERPs.
Robots.txt is one option for reducing the amount of duplicate content available for crawling. There are other techniques for notifying Google about duplicate content, such as canonicalization, which Google recommends. However, you can also exclude duplicate content from robots.txt files to save the crawl budget.
3. Transfer Link Equity To The Relevant Pages
Internal linking equity is a unique tool for improving your SEO. In Google’s eyes, your best-performing pages can boost the credibility of your poor and average-performing pages. However, robots.txt files instruct bots to leave once they access a page with the directive.
That is, if they obey your order, they do not follow the linked routes or aspects of the ranking power from these pages. Your link juice is potent, and when you use robots.txt properly. The link equity is directed to the pages you want to enhance rather than those that should be ignored.
Use robots.txt files only for web pages that do not require equity from their on-page links.
4. Set Crawling Instructions For Selected Bots
There is a wide range of bots even within the same search engine. Aside from the main “Googlebot,” Google has crawlers such as Googlebot Images, Googlebot Videos, AdsBot, and others. With robots.txt, you can prompt crawlers away from files that you don’t want to show up in searches.
For example, if you want to prevent files from appearing in Google Images searches, you can add block directives to your image files.
Robots.txt files in personal directories can prevent search engine bots, but keep in mind that this does not protect confidential and sensitive information.
How Do I Create A Robots.Txt File For My Website?
One or more rules are contained in a robots.txt file. But how to create a robots.txt file? Follow the simple rules for robots.txt files, which are the formatting, syntax, and location rules & regulations.
Here are some formatting rules:
- Place the robots.txt file in the root directory of your website (e.g., https://example.com/robots.txt).
- For subdomains, place a separate robots.txt file within the root directory of each subdomain (e.g., http://subdomain.example.com/robots.txt).
- Ensure the filename is in lowercase (robots.txt).
- Only one ‘robots.txt’ file should exist per domain or subdomain.
- If the file is absent, web crawlers will assume there are no restrictions, which might result in a 404 error when they attempt to access it.
In terms of format and location, a robots.txt file can be created for almost any text editor. The text editor must be capable of producing standard ASCII or UTF-8 text files.
Use a word processor instead, as these programs frequently save files in a specific format and may insert unusual characters (e.g., curly quotes), which can misguide crawlers.
Robots.txt Best Practices
Always verify that your robots.txt does not inadvertently block important content from being crawled.
- Understand that while robots.txt can prevent crawling, it does not avoid indexing URLs discovered through other means.
- To protect sensitive information, rely on secure methods like encryption and use noindex directives correctly implemented through meta tags or HTTP headers, not robots.txt.
- Tailoring access for different search engine crawlers using specific user-agent directives in robots.txt can be beneficial for controlling how your site is crawled and indexed.
- Be aware that search engines recognize changes to robots.txt over time, and there’s no immediate way to force a refresh. Use SuiteJar or Google Search Console, which other search engines provide, to test and verify your robots.txt directives.
Common Robots.txt File Mistakes to Avoid
Take note of the following common mistakes when creating your robots.txt file and prevent them from enhancing your site’s crawlability and internet performance.
i. Failure To Send A Robots.txt File To Google
Always keep your robots.txt file up to date and submit it to Google. If you made minor changes, such as adding robots.txt to deny all instructions to specific user agents or deleting robots to block all directives, make sure to click the send button. Google will be informed of any changes you make to your robots.txt file this way.
ii. Not Using A Good SEO Tool
A good and effective SEO tool like SuiteJar helps you ensure whether the robots.txt file is present on your website or not.
You can use its website auditor feature to audit your website and check the insights. Using its website auditor feature, you can thoroughly examine your website, identifying any technical, content, or SEO-related issues.
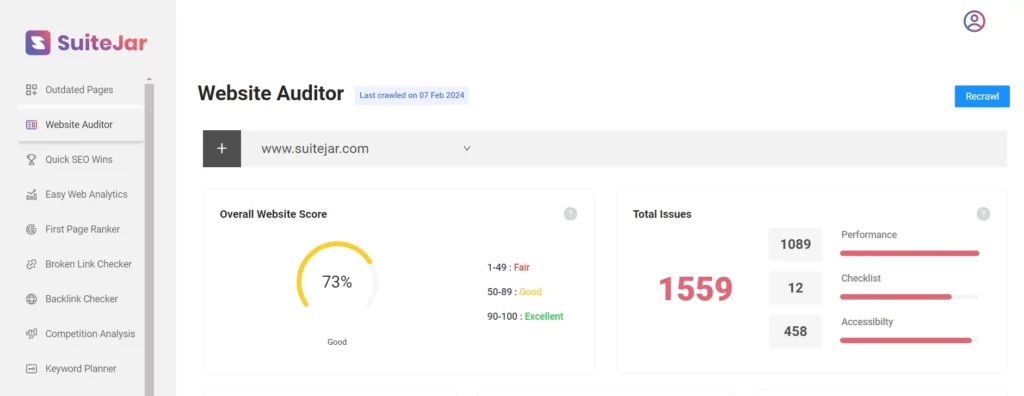
Apart from this, SuiteJar provides a backlinks checker, keyword planner & tracker, broken link checker, and much more.

iii. Using The Incorrect Robots.txt No Index Directives
While doing so, you risk your website not being crawled by Google bots, losing valuable traffic, and, worst of all, experiencing a sudden drop in search engine rankings.
iv. Improper Use Of Robots.txt Results In The Denial Of All Instructions, Wildcards, Trailing Strikes, And Other Directives.
Before saving and sending your robot.txt file to search engines such as Google, always run it through a robots.txt validator to ensure that no robots.txt errors are generated.
v. Ignore Robots.txt Validator Reports
There is a purpose for a robots.txt validator. So, make the most of your robots.txt checker and other software to make sure that your robots.txt optimal solution efforts for SEO are on track.
Final Thoughts
The robots.txt file allows you to prevent robots from accessing sections of your website, which is useful if a section of your page is private or the content is not vital for search engines.
As a result, a robots.txt file is a crucial tool for controlling the indexing of your webpage. You can also use a site audit tool to get their insights and take appropriate actions accordingly.
Trying to deal with robots.txt optimization and other professional SEO issues can be taxing, particularly if you lack sufficient resources, workforce, and functionality. Don’t put yourself through unnecessary stress by dealing with website problems that professionals can quickly resolve.

FAQs (Frequently Asked Questions)
1. What if you do not have a robots.txt file?
If a robots.txt file is absent, search engine crawlers believe all publicly accessible site pages can be crawled and incorporated into their index.
2. What happens if the robots.txt file isn’t correctly formatted?
It all depends on the situation. If search engines cannot recognize the file’s contents due to a misconfiguration, they will still visit the website and ignore anything in robots.txt.
3. What if I accidentally prevent search engines from viewing my website?
That is a major issue. For beginners, they will not crawl or index any web page from your website and will slowly remove any existing webpage in their index.
1 Comments

10 Strategies to Boost SaaS Startup Marketing Budget with $0 says
2026-01-19 13:18:02[…] SEO: Technical SEO deals with the overall improvement of your site, and that will include UX, robot.txt, SSL certificates, schema, […]
Proudly from India
![]()
Prudently for the globe.
![]()
Quick Links
Business Address
WeWork Vaswani Chambers 2nd Floor, HD-234, Plot no. 264-265,Dr Annie Besant Rd, Worli Shivaji Nagar,
Municipal Colony, Mumbai,
Maharashtra, 400030 hello@suitejar.com

SuiteJar is a Startup India approved startup.